


When people program new deep learning AI models — those that can focus on the right features of data by themselves — the vast majority rely on optimization algorithms, or optimizers, to ensure the models have a high enough rate of accuracy. But one of the most commonly used optimizers — derivative-based optimizers— run into trouble handling real-world applications.
In a new paper, researchers from DeepMind propose a new way: Optimization by PROmpting (OPRO), a method that uses AI large language models (LLM) as optimizers. The unique aspect of this approach is that the optimization task is defined in natural language rather than through formal mathematical definitions.
The researchers write, “Instead of formally defining the optimization problem and deriving the update step with a programmed solver, we describe the optimization problem in natural language, then instruct the LLM to iteratively generate new solutions based on the problem description and the previously found solutions.”
The technique is highly adaptable. By simply modifying the problem description or adding specific instructions, the LLM can be guided to solve a wide array of problems.
The researchers found that, on small-scale optimization problems, LLMs can generate effective solutions through prompting alone, sometimes matching or even surpassing the performance of expert-designed heuristic algorithms. However, the true potential of OPRO lies in its ability to optimize LLM prompts to get maximum accuracy from the models.
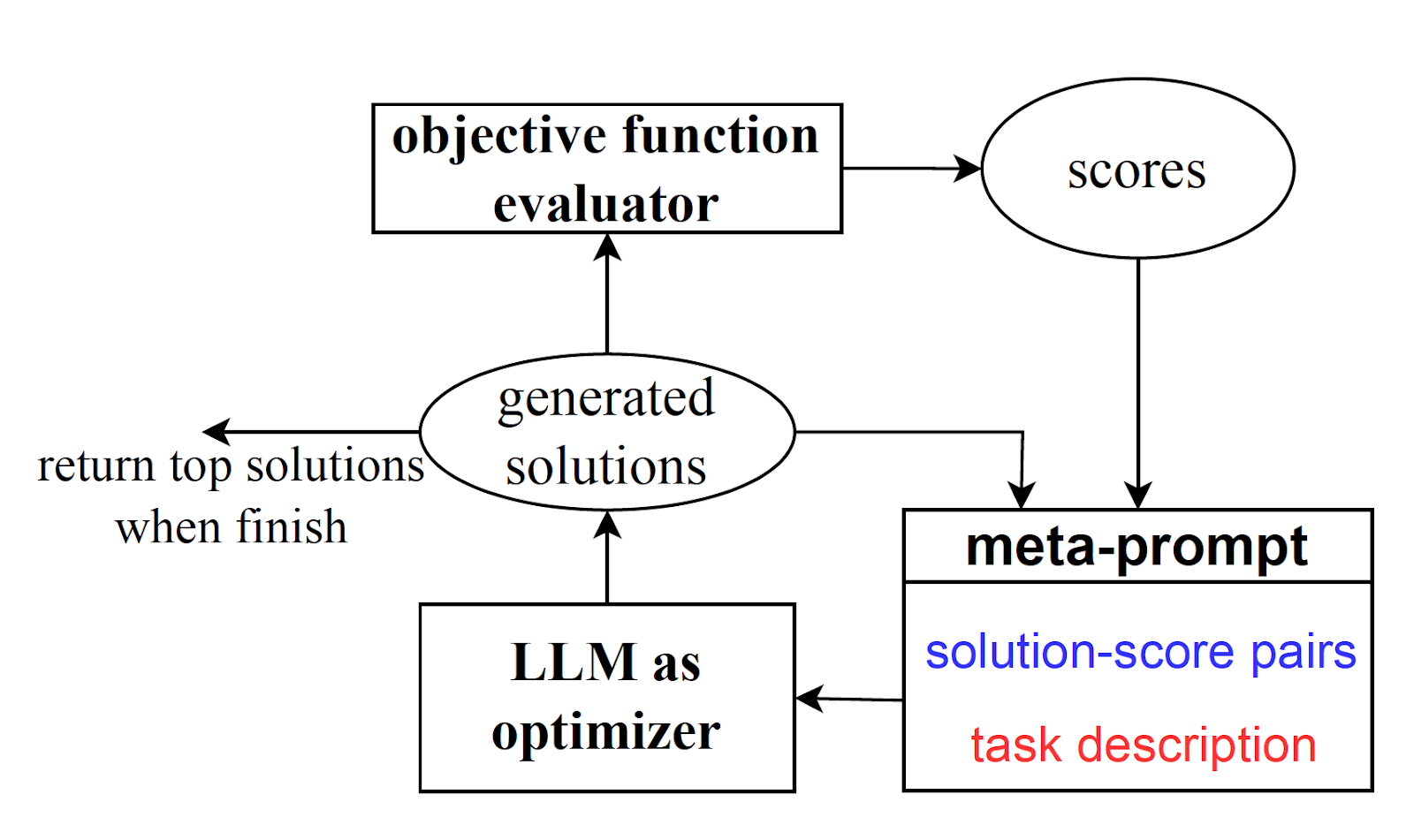
The process of OPRO begins with a “meta-prompt” as input. This meta-prompt includes a natural language description of the task at hand, along with a few examples of problems, placeholders for prompt instructions, and corresponding solutions.
As the optimization process unfolds, the large language model (LLM) generates candidate solutions. These are based on the problem description and the previous solutions included in the meta-prompt.
OPRO then evaluates these candidate solutions, assigning each a quality score. Optimal solutions and their scores are added to the meta-prompt, enriching the context for the next round of solution generation. This iterative process continues until the model stops proposing better solutions.
“The main advantage of LLMs for optimization is their ability of understanding natural language, which allows people to describe their optimization tasks without formal specifications,” the researchers explain.
This means users can specify target metrics such as “accuracy” while also providing other instructions. For instance, they might request the model to generate solutions that are both concise and broadly applicable.
OPRO also capitalizes on LLMs’ ability to detect in-context patterns. This enables the model to identify an optimization trajectory based on the examples included in the meta-prompt. The researchers note, “Including optimization trajectory in the meta-prompt allows the LLM to identify similarities of solutions with high scores, encouraging the LLM to build upon existing good solutions to construct potentially better ones without the need of explicitly defining how the solution should be updated.”
To validate the effectiveness of OPRO, the researchers tested it on two well-known mathematical optimization problems: linear regression and the “traveling salesman problem.” While OPRO might not be the most optimal way to solve these problems, the results were promising.
“On both tasks, we see LLMs properly capture the optimization directions on small-scale problems merely based on the past optimization trajectory provided in the meta-prompt,” the researchers report.
Experiments show that prompt engineering can dramatically affect the output of a model. For instance, appending the phrase “let’s think step by step” to a prompt can coax the model into a semblance of reasoning, causing it to outline the steps required to solve a problem. This can often lead to more accurate results.
However, it’s crucial to remember that this doesn’t imply LLMs possess human-like reasoning abilities. Their responses are highly dependent on the format of the prompt, and semantically similar prompts can yield vastly different results. The DeepMind researchers write, “Optimal prompt formats can be model-specific and task-specific.”
The true potential of Optimization by PROmpting lies in its ability to optimize prompts for LLMs like OpenAI’s ChatGPT and Google’s PaLM. It can guide these models to find the best prompt that maximizes task accuracy.
“OPRO enables the LLM to gradually generate new prompts that improve the task accuracy throughout the optimization process, where the initial prompts have low task accuracies,” they write.
To illustrate this, consider the task of finding the optimal prompt to solve word-math problems. An “optimizer LLM” is provided with a meta-prompt that includes instructions and examples with placeholders for the optimization prompt (e.g., “Let’s think step by step”). The model generates a set of different optimization prompts and passes them on to a “scorer LLM.” This scorer LLM tests them on problem examples and evaluates the results. The best prompts, along with their scores, are added to the beginning of the meta-prompt, and the process is repeated.
The researchers evaluated this technique using several LLMs from the PaLM and GPT families. They found that “all LLMs in our evaluation are able to serve as optimizers, which consistently improve the performance of the generated prompts through iterative optimization until convergence.”
For example, when testing OPRO with PaLM-2 on the GSM8K, a benchmark of grade school math word problems, the model produced intriguing results. It began with the prompt “Let’s solve the problem,” and generated other strings, such as “Let’s think carefully about the problem and solve it together,” “Let’s break it down,” “Let’s calculate our way to the solution,” and finally “Let’s do the math,” which provided the highest accuracy.
In another experiment, the most accurate result was generated when the string “Take a deep breath and work on this problem step-by-step,” was added before the LLM’s answer.
These results are both fascinating and somewhat disconcerting. To a human, all these instructions would carry the same meaning, but they triggered very different behavior in the LLM. This serves as a caution against anthropomorphizing LLMs and highlights how much we still have to learn about their inner workings.
However, the advantage of OPRO is clear. It provides a systematic way to explore the vast space of possible LLM prompts and find the one that works best for a specific type of problem. How it will hold out in real-world applications remains to be seen, but this research can be a step forward toward our understanding of how LLMs work.
When people program new deep learning AI models — those that can focus on the right features of data by themselves — the vast majority rely on optimization algorithms, or optimizers, to ensure the models have a high enough rate of accuracy. But one of the most commonly used optimizers — derivative-based optimizers— run into trouble handling real-world applications.
In a new paper, researchers from DeepMind propose a new way: Optimization by PROmpting (OPRO), a method that uses AI large language models (LLM) as optimizers. The unique aspect of this approach is that the optimization task is defined in natural language rather than through formal mathematical definitions.
The researchers write, “Instead of formally defining the optimization problem and deriving the update step with a programmed solver, we describe the optimization problem in natural language, then instruct the LLM to iteratively generate new solutions based on the problem description and the previously found solutions.”
The technique is highly adaptable. By simply modifying the problem description or adding specific instructions, the LLM can be guided to solve a wide array of problems.
The researchers found that, on small-scale optimization problems, LLMs can generate effective solutions through prompting alone, sometimes matching or even surpassing the performance of expert-designed heuristic algorithms. However, the true potential of OPRO lies in its ability to optimize LLM prompts to get maximum accuracy from the models.
How Optimization by PROmpting works
The process of OPRO begins with a “meta-prompt” as input. This meta-prompt includes a natural language description of the task at hand, along with a few examples of problems, placeholders for prompt instructions, and corresponding solutions.
As the optimization process unfolds, the large language model (LLM) generates candidate solutions. These are based on the problem description and the previous solutions included in the meta-prompt.
OPRO then evaluates these candidate solutions, assigning each a quality score. Optimal solutions and their scores are added to the meta-prompt, enriching the context for the next round of solution generation. This iterative process continues until the model stops proposing better solutions.
“The main advantage of LLMs for optimization is their ability of understanding natural language, which allows people to describe their optimization tasks without formal specifications,” the researchers explain.
This means users can specify target metrics such as “accuracy” while also providing other instructions. For instance, they might request the model to generate solutions that are both concise and broadly applicable.
OPRO also capitalizes on LLMs’ ability to detect in-context patterns. This enables the model to identify an optimization trajectory based on the examples included in the meta-prompt. The researchers note, “Including optimization trajectory in the meta-prompt allows the LLM to identify similarities of solutions with high scores, encouraging the LLM to build upon existing good solutions to construct potentially better ones without the need of explicitly defining how the solution should be updated.”
To validate the effectiveness of OPRO, the researchers tested it on two well-known mathematical optimization problems: linear regression and the “traveling salesman problem.” While OPRO might not be the most optimal way to solve these problems, the results were promising.
“On both tasks, we see LLMs properly capture the optimization directions on small-scale problems merely based on the past optimization trajectory provided in the meta-prompt,” the researchers report.
Optimizing LLM prompts with OPRO
Experiments show that prompt engineering can dramatically affect the output of a model. For instance, appending the phrase “let’s think step by step” to a prompt can coax the model into a semblance of reasoning, causing it to outline the steps required to solve a problem. This can often lead to more accurate results.
However, it’s crucial to remember that this doesn’t imply LLMs possess human-like reasoning abilities. Their responses are highly dependent on the format of the prompt, and semantically similar prompts can yield vastly different results. The DeepMind researchers write, “Optimal prompt formats can be model-specific and task-specific.”
The true potential of Optimization by PROmpting lies in its ability to optimize prompts for LLMs like OpenAI’s ChatGPT and Google’s PaLM. It can guide these models to find the best prompt that maximizes task accuracy.
“OPRO enables the LLM to gradually generate new prompts that improve the task accuracy throughout the optimization process, where the initial prompts have low task accuracies,” they write.
To illustrate this, consider the task of finding the optimal prompt to solve word-math problems. An “optimizer LLM” is provided with a meta-prompt that includes instructions and examples with placeholders for the optimization prompt (e.g., “Let’s think step by step”). The model generates a set of different optimization prompts and passes them on to a “scorer LLM.” This scorer LLM tests them on problem examples and evaluates the results. The best prompts, along with their scores, are added to the beginning of the meta-prompt, and the process is repeated.
The researchers evaluated this technique using several LLMs from the PaLM and GPT families. They found that “all LLMs in our evaluation are able to serve as optimizers, which consistently improve the performance of the generated prompts through iterative optimization until convergence.”
For example, when testing OPRO with PaLM-2 on the GSM8K, a benchmark of grade school math word problems, the model produced intriguing results. It began with the prompt “Let’s solve the problem,” and generated other strings, such as “Let’s think carefully about the problem and solve it together,” “Let’s break it down,” “Let’s calculate our way to the solution,” and finally “Let’s do the math,” which provided the highest accuracy.
In another experiment, the most accurate result was generated when the string “Take a deep breath and work on this problem step-by-step,” was added before the LLM’s answer.
These results are both fascinating and somewhat disconcerting. To a human, all these instructions would carry the same meaning, but they triggered very different behavior in the LLM. This serves as a caution against anthropomorphizing LLMs and highlights how much we still have to learn about their inner workings.
However, the advantage of OPRO is clear. It provides a systematic way to explore the vast space of possible LLM prompts and find the one that works best for a specific type of problem. How it will hold out in real-world applications remains to be seen, but this research can be a step forward toward our understanding of how LLMs work.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.
Author: Ben Dickson
Source: Venturebeat
Reviewed By: Editorial Team
