


Machine learning systems have been mopping the floor with their human opponents for well over a decade now (seriously, that first Watson Jeopardy win was all the way back in 2011), though the types of games they excel at are rather limited. Typically competitive board or video games using a limited play field, sequential moves and at least one clearly-defined opponent, any game that requires the crunching of numbers is to their advantage. Diplomacy, however, requires very little computation, instead demanding players negotiate directly with their opponents and make respective plays simultaneously — things modern ML systems are generally not built to do. But that hasn’t stopped Meta researchers from designing an AI agent that can negotiate global policy positions as well as any UN ambassador.
Diplomacy was first released in 1959 and works like a more refined version of RISK where between two and seven players assume the roles of a European power and attempt to win the game by conquering their opponents’ territories. Unlike RISK where the outcome of conflicts are decided by a simple the roll of the dice, Diplomacy demands players first negotiate with one another — setting up alliances, backstabbing, all that good stuff — before everybody moves their pieces simultaneously during the following game phase. The abilities to read and manipulate opponents, convince players to form alliances and plan complex strategies, navigate delicate partnerships and know when to switch sides, are all a huge part of the game — and all skills that machine learning systems generally lack.
On Wednesday, Meta AI researchers announced that they had surmounted those machine learning shortcomings with CICERO, the first AI to display human-level performance in Diplomacy. The team trained Cicero on 2.7 billion parameters over the course of 50,000 rounds at webDiplomacy.net, an online version of the game, where it ended up in second place (out of 19 participants) in a 5-game league tournament, all while doubling up the average score of its opponents.
The AI agent proved so adept “at using natural language to negotiate with people in Diplomacy that they often favored working with CICERO over other human participants,” the Meta team noted in a press release Wednesday. “Diplomacy is a game about people rather than pieces. If an agent can’t recognize that someone is likely bluffing or that another player would see a certain move as aggressive, it will quickly lose the game. Likewise, if it doesn’t talk like a real person — showing empathy, building relationships, and speaking knowledgeably about the game — it won’t find other players willing to work with it.”
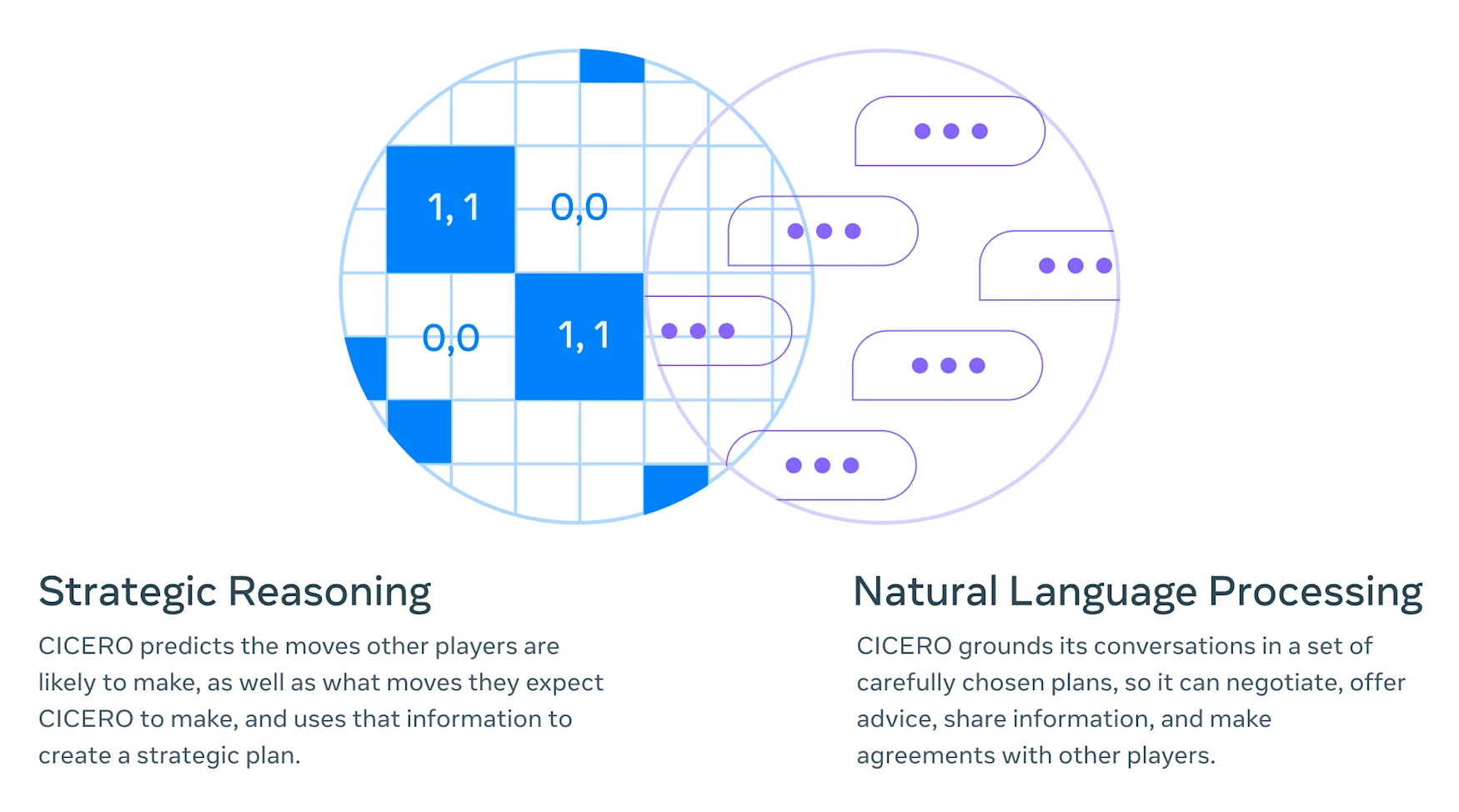
Essentially, Cicero combines the strategic mindset from Pluribot or AlphaGO with the natural language processing (NLP) abilities of Blenderbot or GPT-3. The agent is even capable of forethought. “Cicero can deduce, for example, that later in the game it will need the support of one particular player, and then craft a strategy to win that person’s favor – and even recognize the risks and opportunities that that player sees from their particular point of view,” the research team noted.
The agent does not train through a standard reinforcement learning scheme as similar systems do. The Meta team explains that doing so would lead to suboptimal performance as, “relying purely on supervised learning to choose actions based on past dialogue results in an agent that is relatively weak and highly exploitable.”
Instead Cicero uses “iterative planning algorithm that balances dialogue consistency with rationality.” It will first predict its opponents’ plays based on what happened during the negotiation round, as well as what play it thinks its opponents think it will make before “iteratively improving these predictions by trying to choose new policies that have higher expected value given the other players’ predicted policies, while also trying to keep the new predictions close to the original policy predictions.” Easy, right?
The system is not yet fool-proof, as the agent will occasionally get too clever and wind up playing itself by taking contradictory negotiating positions. Still, its performance in these early trials is superior to that of many human politicians. Meta plans to continue developing the system to “serve as a safe sandbox to advance research in human-AI interaction.”
Author: A. Tarantola
Source: Engadget
