

The team of AI researchers known as Nous Research is currently doing something unique in the fast-moving space of generative AI (at least to my knowledge): Nous is in the midst of pre-training a new 15-billion parameter large language model (LLM) using machines distributed around the internet and the world, avoiding the need to concentrate model development as it traditionally has been in expensive, power-hungry AI data centers and “superclusters” of graphics processing units (GPUs) such as the one recently completed by Elon Musk’s xAI in Memphis, Tennessee.
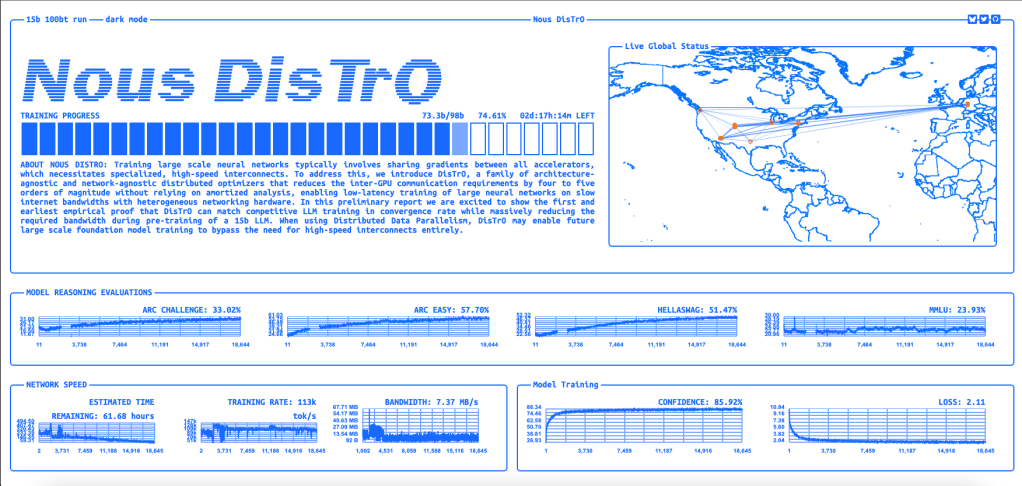
Furthermore, Nous is livestreaming the pre-training process on a dedicated website — distro.nousresearch.com — showing how well it is performing on evaluation benchmarks as it goes along and also a simple map of the various locations of the training hardware behind the exercise, including several places in the U.S. and Europe.
As of the time of this article’s publication, there are roughly 57 hours (2.3 days) left in the pre-training run with more than 75% of the process completed.
Pre-training is the first of two and arguably most foundational aspect of training an LLM, as it involves training the model on a vast corpus of text data to learn the statistical properties and structures of language. The model processes extensive text datasets, capturing patterns, grammar, and contextual relationships between words. This stage equips the model with a broad understanding of language, enabling it to generate coherent text and perform various language-related tasks.
Following pre-training, the model undergoes fine-tuning on a more specific dataset tailored to particular tasks or domains.
If successful, Nous will prove that it is possible to train frontier-class LLMs without the need for expensive superclusters or low latency transmission, using a novel, open source training method. It could usher in a new era of distributed AI training as a major, or potentially dominant, source of new AI models and shift the balance of power in gen AI away from well-moneyed big tech companies and towards smaller groups and non-corporate actors.
Nous DisTrO: the tech behind the training exercise
Nous, which made headlines earlier this year for the release of its permissive and existentially conflicted Meta Llama 3.1 variant Hermes 3 and its overall mission to make AI development personalized and unrestricted, is using its open-source distributed training technology called Nous DisTrO (Distributed Training Over-the-Internet), which Nous initially published in a research paper back in August 2024.
According to Nous Research’s recent publication, DisTrO reduces inter-GPU communication bandwidth requirements by up to 10,000x during pre-training. This innovation allows models to be trained on slower and more affordable internet connections—potentially as low as 100Mbps download and 10Mbps upload speeds—while maintaining competitive convergence rates and loss curves.
DisTrO’s core breakthrough lies in its ability to efficiently compress the data exchanged between GPUs without sacrificing model performance.
As described in an August 2024 VentureBeat article, the method reduced communication requirements from 74.4 gigabytes to just 86.8 megabytes during a test using a Llama 2 architecture, an efficiency gain of nearly 857x. This dramatic improvement paves the way for a new era of decentralized, collaborative AI research.
DisTrO builds upon earlier work on Decoupled Momentum Optimization (DeMo), an algorithm designed to reduce inter-GPU communication by several orders of magnitude while maintaining training performance comparable to traditional methods.
Both the DeMo algorithm and the DisTrO stack are part of Nous Research’s ongoing mission to decentralize AI capabilities and bring advanced AI development to a broader audience.
The team also made the DeMo algorithm available as open-source code on GitHub, inviting researchers and developers worldwide to experiment with and build upon their findings.
Hardware partners
The pre-training of Nous Research’s 15-billion-parameter language model involved contributions from several notable partners, including Oracle, Lambda Labs, Northern Data Group, Crusoe Cloud, and the Andromeda Cluster.
Together, they provided the heterogeneous hardware necessary to test DisTrO’s capabilities in a real-world distributed environment.
Profound implications for future AI model development
The implications of DisTrO extend beyond technical innovation. By reducing the reliance on centralized data centers and specialized infrastructure, DisTrO offers a path to a more inclusive and collaborative AI research ecosystem.
Smaller institutions, independent researchers, and even hobbyists with access to consumer-grade internet and GPUs can potentially train large models—a feat previously reserved for companies with significant capital and expertise.
Diederik P. Kingma, a co-author of the research paper and co-inventor of the Adam optimizer, joined Nous Research as a collaborator on the development of DeMo and DisTrO. Kingma’s contributions, alongside those of Nous Research co-founders Bowen Peng and Jeffrey Quesnelle, lend credibility to the project and signal its potential impact on the broader AI community.
Next steps
Nous Research has opened the door to a future where AI development is no longer dominated by a handful of corporations. Their work on DisTrO demonstrates that with the right optimizations, large-scale AI models can be trained efficiently in a decentralized manner.
While the current demonstration used cutting-edge GPUs like the Nvidia H100, the scalability of DisTrO to less specialized hardware remains an area for further exploration.
As Nous Research continues to refine its methods, the potential applications of this technology—ranging from decentralized federated learning to training diffusion models for image generation—could redefine the boundaries of AI innovation.
Author: Carl Franzen
Source: Venturebeat
Reviewed By: Editorial Team
