


Due to physical limitations, cameras can only become so small before they simply cannot shrink anymore. But a new lensless camera design could change that.
Researchers have also been steadily moving towards a computational approach rather than on that relies on optics being a set distance from the image sensor in order to focus light upon it.
At the Tokyo Institute of Technology in Japan, scientists have been hard at work applying machine learning to the idea that a camera may not need a lens at all. Much like the Cambrian camera or the sun telescope, it just needs a new way to see the light. And while this kind of research has been going on for years, a new approach is applying machine learning to make the images more focused and lifelike.

While most designs for a lensless camera rely on an image sensor that interacts with light through a mask, and then an algorithm to measure that light to reconstruct the image, the new approach takes things a step further by applying machine learning to analyze each pixel and how they affect one another. With this data, convolutional neural networks (CNN) are then applied to reconstruct the image.
The problem is while an image emerges, it isn’t sharp enough to provide any detail or definition without applying a lot of power and energy to solving the computational problem. Without a lens to focus the light, the image sensor just receives a blob of encoded patterns of the light data interacting on the mask itself. Therefore, the sensor has to chug away with a lot of computational power to rebuild the image from that data.
“CNN processes the image based on the relationships of neighboring ‘local’ pixels, whereas lensless optics transform local information in the scene into overlapping ‘global’ information on all the pixels of the image sensor, through a property called ‘multiplexing,” the researchers explain.
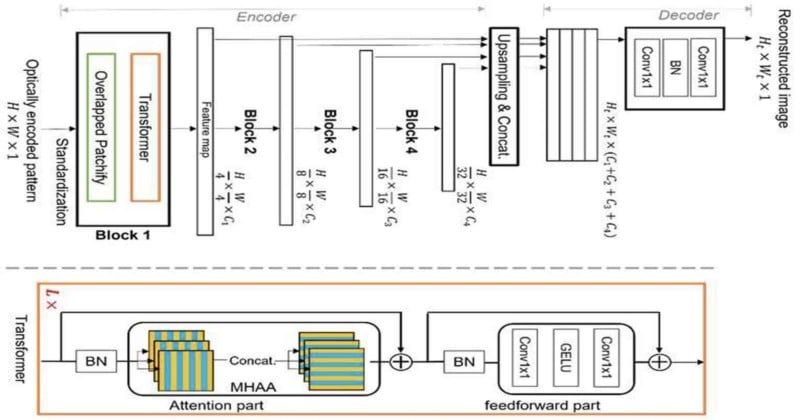
This is where the new approach comes in. Using an array of “Vision Transformers,” global reasoning can be applied across the entire image sensor in order to identify and analyze the light as it strikes the sensor.
“The novelty of the algorithm lies in the structure of the multistage transformer blocks with overlapped ‘patchify’ modules,” the researchers explain in the paper published to Phys and spotted by DPReview.
“This allows it to efficiently learn image features in a hierarchical representation. Consequently, the proposed method can well address the multiplexing property and avoid the limitations of conventional CNN-based deep learning, allowing better image reconstruction.”
This new approach goes far beyond the CNN process and relies on neural networks and these connected transformers, but the results yield reduced errors while requiring less time and resources for analysis and reconstruction. As such, lensless photos can be taken in real-time, much like with a conventional camera, and the research suggests that with additional development, higher-quality images can be produced with greater sharpness and detail.
Additionally, lensless cameras can become ultra-small, which has been the stated goal of lensless camera research. If a camera doesn’t have to obey the rules of physics when it comes to light bending and the distance required to make a focused image, then there could be no limit as to how small a camera can become. Overall, lenless camera research has produced a one-pixel wide camera image in 2013, and if this new approach can go beyond that to the micron level, then cameras could be so small as to be invisible. All that remains is refining the approach.
“Without the limitations of a lens, the lensless camera could be ultra-miniature,” says Prof. Masahiro Yamaguchi of Tokyo Tech, “which could allow new applications that are beyond our imagination.”
Image credits: Photos via “‘Lensless’ imaging through advanced machine learning for next generation image sensing solutions,” Tokyo Institute of Technology
Author: James DeRuvo
Source: Petapixel
