


Check out all the on-demand sessions from the Intelligent Security Summit here.
2022 was a great year for generative AI, with the release of models such as DALL-E 2, Stable Diffusion, Imagen, and Parti. And 2023 seems to follow on that path as Google introduced its latest text-to-image model, Muse, earlier this month.
Like other text-to-image models, Muse is a deep neural network that takes a text prompt as input and generates an image that fits the description. However, what sets Muse apart from its predecessors is its efficiency and accuracy. By building on the experience of previous work in the field and adding new techniques, the researchers at Google have managed to create a generative model that requires less computational resources and makes progress on some of the problems that other generative models suffer from.
Google’s Muse uses token-based image generation
Muse builds on previous research in deep learning, including large language models (LLMs), quantized generative networks, and masked generative image transformers.
“A strong motivation was our interest in unifying image and text generation through the use of tokens,” said Dilip Krishnan, research scientist at Google. “Muse is built on ideas in MaskGit, a previous paper from our group, and on masking modeling ideas from large language models.”
Event
Intelligent Security Summit On-Demand
Learn the critical role of AI & ML in cybersecurity and industry specific case studies. Watch on-demand sessions today.
Muse leverages conditioning on pretrained language models used in prior work, as well as the idea of cascading models, which it borrows from Imagen. One of the interesting differences between Muse and other similar models is generating discrete tokens instead of pixel-level representations, which makes the model’s output much more stable.
Like other text-to-image generators, Muse is trained on a large corpus of image-caption pairs. A pretrained LLM processes the caption and generates an embedding, a multidimensional numerical representation of the text description. At the same time, a cascade of two image encoder-decoders transforms different resolutions of the input image into a matrix of quantized tokens.
During the training, the model trains a base transformer and a super-resolution transformer to align the text embeddings with the image tokens and use them to reproduce the image. The model tunes its parameters by randomly masking image tokens and trying to predict them.
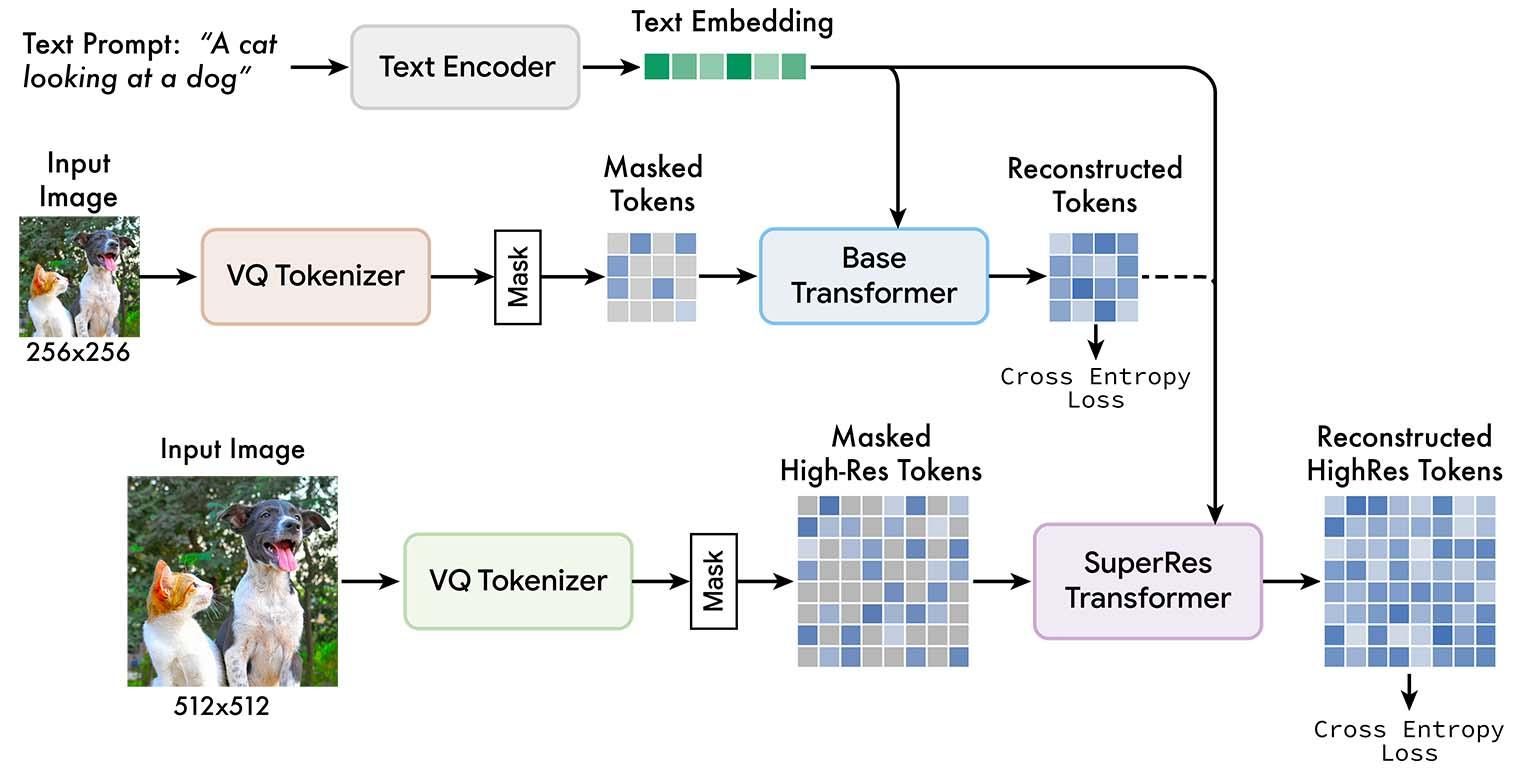
Once trained, the model can generate the image tokens from the text embedding of a new prompt and use the image tokens to create novel high-resolution images.
According to Krishnan, one of the innovations in Muse is parallel decoding in token space, which is fundamentally different from both diffusion and autoregressive models. Diffusion models use progressive denoising. Autoregressive models use serial decoding. The parallel decoding in Muse allows for very good efficiency without loss in visual quality.
“We consider Muse’s decoding process analogous to the process of painting — the artist starts with a sketch of the key region, then progressively fills the color, and refines the results by tweaking the details,” Krishnan said.
Superior results from Google Muse
Google has not released Muse to the public yet due to the possible risks of the model being used “for misinformation, harassment and various types of social and cultural biases.”
But according to the results published by the research team, Muse matches or outperforms other state-of-the-art models on CLIP and FID scores, two metrics that measure the quality and accuracy of the images created by generative models.
Muse is also faster than Stable Diffusion and Imagen due to its use of discrete tokens and parallel sampling method, which reduce the number of sampling iterations required to generate high-quality images.
Interestingly, Muse improves on other models in problem areas such as cardinality (prompts that include a specific number of objects), compositionality (prompts that describe scenes with multiple objects that are related to each other) and text rendering. However, the model still fails on prompts that require rendering long texts and large numbers of objects.
One of the crucial advantages of Muse is its ability to perform editing tasks without the need for fine-tuning. Some of these features include inpainting (replacing part of an existing image with generated graphics), outpainting (adding details around an existing image) and mask-free editing (e.g., changing the background or specific objects in the image).
“For all generative models, refining and editing prompts is a necessity — the efficiency of Muse enables users to do this refinement quickly, thus helping the creative process,” Krishnan said. “The use of token-based masking enables a unification between the methods used in text and images; and can be potentially used for other modalities.”
Muse is an example of how bringing together the right techniques and architectures can help make impressive advances in AI. The team at Google believes Muse still has room for improvement.
“We believe generative modeling is an emerging research topic,” Krishnan said. “We are interested in directions such as how to customize editing based on the Muse model and further accelerate the generative process. These will also build on existing ideas in the literature.”
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.
Author: Ben Dickson
Source: Venturebeat
