


In 2016, Alphabet’s DeepMind came out with AlphaGo, an AI which consistently beat the best human Go players. One year later, the subsidiary went on to refine its work, creating AlphaGo Zero. Where its predecessor learned to play Go by observing amateur and professional matches, AlphaGo Zero mastered the ancient game by simply playing against itself. DeepMind then created AlphaZero, which could play Go, chess and shogi with a single algorithm. What tied all those AIs together is that they knew the rules of the games they had to master going into their training. DeepMind’s latest AI, MuZero, didn’t need to be told the rules of go, chess, shogi and a suite of Atari games to master them. Instead, it learned them all on its own and is just as capable or better at them than any of DeepMind’s previous algorithms.
Creating an algorithm that can adapt to a situation where it doesn’t know all the rules governing a simulation, but it can still find a way to plan for success has been a challenge AI researchers have been trying to solve for a while. DeepMind has consistently attempted to tackle the problem using an approach called lookahead search. With this method, an algorithm will consider future states to plan a course of action. The best way to wrap your head around this is to think about how you would play a strategy game like chess or Starcraft II. Before making a move, you’ll consider how your opponent will react and try to plan accordingly. In much the same way, an AI that utilizes the lookahead method will try to plan several moves in advance. Even with a game as relatively straightforward as chess, it’s impossible to consider every possible future state, so instead an AI will prioritize the ones that are most likely to win the match.

The problem with this approach is that most real-world situations, and even some games, don’t have a simple set of rules governing how they operate. So some researchers have tried to get around the problem by using an approach that attempts to model how a particular game or scenario environment will affect an outcome and then use that knowledge to make a plan. The drawback of this system is that some domains are so complex that modeling every aspect is nearly impossible. This has proven to be the case with most Atari games, for instance.
In a way, MuZero combines the best of both worlds. Rather than modeling everything, it only attempts to consider those factors that are important to making a decision. As DeepMind points out, this is something you do as a human being. When most people look out the window and see dark clouds forming on the horizon, they generally don’t get caught up thinking about things like condensation and pressure fronts. They instead think about how they should dress to stay dry if they go outside. MuZero does something similar.
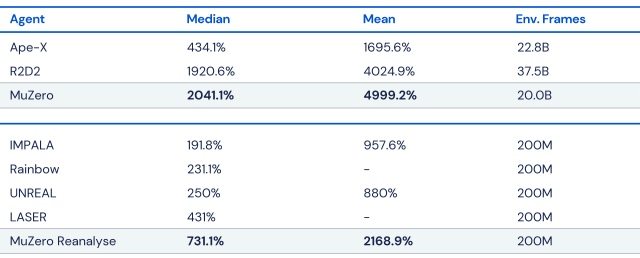
It takes into account three factors when it has to make a decision. It will consider the outcome of its previous decision, the current position it finds itself in and the best course of action to take next. That seemingly simple approach makes MuZero the most effective algorithm DeepMind made to date. In its testing, it found MuZero was as good as AlphaZero at chess, Go and shogi, and better than all its previous algorithms, including Agent57, at Atari games. It also found that the more time it gave MuZero to consider an action, the better it performed. DeepMind also conducted testing in which it put a limit on the number of simulations MuZero could complete in advance of committing to a move in Ms Pac-Man. In those tests, it found MuZero was still able to achieve good results.
Putting up high scores in Atari games is all well and good, but what about the practical applications of DeepMind’s latest research? In a word, they could be groundbreaking. While we’re not there yet, MuZero is the closest researchers have come to developing a general-purpose algorithm. The subsidiary says MuZero learning capabilities could one day help it tackle complex problems in fields like robotics where there aren’t straightforward rules.
Author: Igor Bonifacic, @igorbonifacic
10h ago
Source: Engadget
