


Check out all the on-demand sessions from the Intelligent Security Summit here.
It’s been less than 18 months since we published our last MAD (Machine Learning, Artificial Intelligence and Data) landscape, and there have been dramatic developments in that time.
When we left, the data world was booming in the wake of the gigantic Snowflake IPO with a whole ecosystem of startups organizing around it. Since then, of course, public markets crashed, a recessionary economy appeared and VC funding dried up. A whole generation of data/AI startups has had to adapt to a new reality.
Meanwhile, the last few months have seen the unmistakable and exponential acceleration of generative AI, with arguably the formation of a new mini-bubble. Beyond technological progress, AI seems to have gone mainstream with a broad group of non-technical people around the world now getting to experience its power firsthand.
The rise of data, ML and AI has been one of the most fundamental trends in our generation. Its importance goes well beyond the purely technical, with a deep impact on society, politics, geopolitics and ethics. Yet it is a complicated, technical, rapidly evolving world that can be confusing even for practitioners in the space. There’s a jungle of acronyms, technologies, products and companies out there that’s hard to keep a track of, let alone master.
Event
Intelligent Security Summit On-Demand
Learn the critical role of AI & ML in cybersecurity and industry specific case studies. Watch on-demand sessions today.

The annual MAD landscape is an attempt at making sense of this vibrant space. Its general philosophy has been to open source work that we would do anyway and start a conversation with the community.
So, here we are again in 2023. This is our ninth annual landscape and “state of the union” of the data and AI ecosystem. Here are the prior versions: 2012, 2014, 2016, 2017, 2018, 2019 (Part I and Part II), 2020 and 2021. As the 2021 version was released late in the year, I skipped 2022 to focus on releasing a new version in the first quarter of 2023, which feels like a more natural publishing time for an annual effort.
This annual state of the union post is organized into four parts:
- Part I: The Landscape (PDF here, interactive version here)
- Part II: Market trends: Financings, M&A and IPOs (or lack thereof)
- Part III: Data infrastructure trends
- Part IV: Trends in ML/AI
MAD 2023, part I: The landscape

After much research and effort, we are proud to present the 2023 version of the MAD landscape. When I say “we,” I mean a little group whose nights will be haunted for months to come by memories of moving tiny logos in and out of crowded little boxes on a PDF: Katie Mills, Kevin Zhang and Paolo Campos. Immense thanks to them. And yes, I meant it when I told them at the onset, “oh, it’s a light project, maybe a day or two, it’ll be fun, please sign here.”
So, here it is (cue in drum roll, smoke machine):

In addition, this year, for the first time, we’re jumping head first into what the youngsters call the “World Wide Web,” with a fully interactive version of the MAD Landscape that should make it fun to explore the various categories in both “landscape” and “card” format.
General approach
We’ve made the decision to keep both data infrastructure and ML/AI on the same landscape. One could argue that those two worlds are increasingly distinct. However, we continue to believe that there is an essential symbiotic relationship between those areas. Data feeds ML/AI models. The distinction between a data engineer and a machine learning engineer is often pretty fluid. Enterprises need to have a solid data infrastructure in place in order before properly leveraging ML/AI.
The landscape is built more or less on the same structure as every annual landscape since our first version in 2012. The loose logic is to follow the flow of data from left to right – from storing and processing to analyzing to feeding ML/AI models and building user-facing, AI-driven or data-driven applications.
We continue to have a separate “open source” section. It’s always been a bit of an awkward organization as we effectively separate commercial companies from the open source project they’re often the main sponsor of. But equally, we want to capture the reality that for one open source project (for example, Kafka), you have many commercial companies and/or distributions (for Kafka – Confluent, Amazon, Aiven, etc.). Also, some open-source projects appearing in the box are not fully commercial companies yet.
The vast majority of the organizations appearing on the MAD landscape are unique companies with a very large number of VC-backed startups. A number of others are products (such as products offered by cloud vendors) or open source projects.
Company selection
This year, we have a total of 1,416 logos appearing on the landscape. For comparison, there were 139 in our first version in 2012.
Each year we say we can’t possibly fit more companies on the landscape, and each year, we need to. This comes with the territory of covering one of the most explosive areas of technology. This year, we’ve had to take a more editorial, opinionated approach to deciding which companies make it to the landscape.
In prior years, we tended to give disproportionate representation to growth-stage companies based on funding stage (typically Series B-C or later) and ARR (when available) in addition to all the large incumbents. This year, particularly given the explosion of brand new areas like generative AI, where most companies are 1 or 2 years old, we’ve made the editorial decision to feature many more very young startups on the landscape.
Disclaimers:
- We’re VCs, so we have a bias towards startups, although hopefully, we’ve done a good job covering larger companies, cloud vendor offerings, open source and the occasional bootstrapped companies.
- We’re based in the US, so we probably over-emphasize US startups. We do have strong representation of European and Israeli startups on the MAD landscape. However, while we have a few Chinese companies, we probably under-emphasize the Asian market as well as Latin America and Africa (which just had an impressive data/AI startup success with the acquisition of Tunisia-born Instadeep by BioNTech for $650M)
Categorization
One of the harder parts of the process is categorization, in particular, what to do when a company’s product offering straddles two or more areas. It’s becoming a more salient issue every year as many startups progressively expand their offering, a trend we discuss in “Part III – Data Infrastructure.”
It would be equally untenable to put every startup in multiple boxes in this already overcrowded landscape. Therefore, our general approach has been to categorize a company based on its core offering, or what it’s mostly known for. As a result, startups generally appear in only one box, even if they do more than just one thing.
We make exceptions for the cloud hyperscalers (many AWS, Azure and GCP products across the various boxes), as well as some public companies (e.g., Datadog) or very large private companies (e.g., Databricks).
What’s new this year
Main changes in “Infrastructure”
- We (finally) killed the Hadoop box to reflect the gradual disappearance of the OG Big Data technology – the end of an era! We decided to keep it one last time in the MAD 2021 landscape to reflect the existing footprint. Hadoop is actually not dead, and parts of the Hadoop ecosystem are still being actively used. But it has declined enough that we decided to merge the various vendors and products supporting Hadoop into Data Lakes (and kept Hadoop and other related projects in our open source category).
- Speaking of data lakes, we rebranded that box to “Data Lakes/Lakehouses” to reflect the lakehouse trend (which we had discussed in the 2021 MAD landscape)
- In the ever-evolving world of databases, we created three new subcategories:
- GPU-accelerated Databases: Used for streaming data and real-time machine learning.
- Vector Databases: Used for unstructured data to power AI applications, see What is a Vector Database?
- Database Abstraction: A somewhat amorphous term meant to capture the emergence of a new group of serverless databases that abstract away a lot of the complexity involved in managing and configuring a database. For more, here’s a good overview: 2023 State of Databases for Serverless & Edge.
- We considered adding an “Embedded Database” category with DuckDB for OLAP, KuzuDB for Graph, SQLite for RDBMS and Chroma for search but had to make hard choices given limited real estate – maybe next year.
- We added a “Data Orchestration” box to reflect the rise of several commercial vendors in that space (we already had a “Data Orchestration” box in “Open Source” in MAD 2021).
- We merged two subcategories, “Data observability” and “Data quality,” into just one box to reflect the fact that companies in the space, while sometimes coming from different angles, are increasingly overlapping – a signal that the category may be ripe for consolidation.
- We created a new “Fully Managed” data infrastructure subcategory. This reflects the emergence of startups that abstract away the complexity of stitching together a chain of data products (see our thoughts on the Modern Data Stack in Part III), saving their customers time, not just on the technical front, but also on contract negotiation, payments, etc.
Main changes in “Analytics”
- For now, we killed the “Metrics Store” subcategory we had created in the 2021 MAD landscape. The idea was that there was a missing piece in the modern data stack. The need for the functionality certainly remains, but it’s unclear whether there’s enough there for a separate subcategory. Early entrants in the space rapidly evolved: Supergrain pivoted, Trace built a whole layer of analytics on top of its metrics store, and Transform was recently acquired by dbt Labs.
- We created a “Customer Data Platform” box, as this subcategory, long in the making, has been heating up.
- At the risk of being “very 2022”, we created a “Crypto/web3 Analytics” box. We continue to believe there are opportunities to build important companies in the space.
Main changes in “Machine Learning/Artificial Intelligence”
- In our 2021 MAD landscape, we had broken down “MLOps” into multiple subcategories: “Model Building,” “Feature Stores” and “Deployment and Production.” In this year’s MAD, we’ve merged everything back into one big MLOps box. This reflects the reality that many vendors’ offerings in the space are now significantly overlapping – another category that’s ripe for consolidation.
- We almost created a new “LLMOps” category next to MLOps to reflect the emergence of a new group of startups focused on the specific infrastructure needs for large language models. But the number of companies there (at least that we are aware of) is still too small and those companies literally just got started.
- We renamed “Horizontal AI” to “Horizontal AI/AGI” to reflect the emergence of a whole new group of research-oriented outfits, many of which openly state artificial general intelligence as their ultimate goal.
- We created a “Closed Source Models” box to reflect the unmistakable explosion of new models over the last year, especially in the field of generative AI. We’ve also added a new box in “Open Source” to capture the open source models.
- We added an “Edge AI” category – not a new topic, but there seems to be acceleration in the space.
Main changes in “Applications”
- We created a new “Applications/Horizontal” category, with subcategories such as code, text, image, video, etc. The new box captures the explosion of new generative AI startups over the last few months. Of course, many of those companies are thin layers on top of GPT and may or may not be around in the next few years, but we believe it’s a fundamentally new and important category and wanted to reflect it on the 2023 MAD landscape. Note that there are a few generative AI startups mentioned in “Applications/Enterprise” as well.
- In order to make room for this new category:
- We deleted the “Security” box in “Applications/Enterprise.” We made this editorial decision because, at this point, just about every one of the thousands of security startups out there uses ML/AI, and we could devote an entire landscape to them.
- We trimmed down the “Applications/Industry” box. In particular, as many larger companies in spaces like finance, health or industrial have built some level of ML/AI into their product offering, we’ve made the editorial decision to focus mostly on “AI-first” companies in those areas.
Other noteworthy changes
- We added a new ESG data subcategory to “Data Sources & APIs” at the bottom to reflect its growing (if sometimes controversial) importance.
- We considerably expanded our “Data Services” category and rebranded it “Data & AI Consulting” to reflect the growing importance of consulting services to help customers facing a complex ecosystem, as well as the fact that some pure-play consulting shops are starting to reach early scale.
MAD 2023, Part II: Financings, M&A and IPOs

“It’s been crazy out there. Venture capital has been deployed at an unprecedented pace, surging 157% year-on-year globally […]. Ever higher valuations led to the creation of 136 newly-minted unicorns […] and the IPO window has been wide open, with public financings up +687%”
Well, that was…last year. Or, more precisely, 15 months ago, in the MAD 2021 post, written pretty much at the top of the market, in September 2021.
Since then, of course, the long-anticipated market turn did occur, driven by geopolitical shocks and rising inflation. Central banks started increasing interest rates, which sucked the air out of an entire world of over-inflated assets, from speculative crypto to tech stocks. Public markets tanked, the IPO window shut down, and bit by bit, the malaise trickled down to private markets, first at the growth stage, then progressively to the venture and seed markets.
We’ll talk about this new 2023 reality in the following order:
- Data/AI companies in the new recessionary era
- Frozen financing markets
- Generative AI, a new financing bubble?
- M&A
MAD companies facing recession
It’s been rough for everyone out there, and Data/AI companies certainly haven’t been immune.
Capital has gone from abundant and cheap to scarce and expensive. Companies of all sizes in the MAD landscape have had to dramatically shift focus from growth at all costs to tight control over their expenses.
Layoff announcements have become a sad part of our daily reality. Looking at popular tracker Layoffs.fyi, many of the companies appearing on the 2023 MAD landscape have had to do layoffs, including, for a few recent examples: Snowplow, Splunk, MariaDB, Confluent, Prisma, Mapbox, Informatica, Pecan AI, Scale AI, Astronomer*, Elastic, UIPath, InfluxData, Domino Data Lab, Collibra, Fivetran, Graphcore, Mode, DataRobot, and many more (to see the full list, filter by industry, using “data”).
For a while in 2022, we were in a moment of suspended reality – public markets were tanking, but underlying company performance was holding strong, with many continuing to grow fast and beating their plans.
Over the last few months, however, overall market demand for software products has started to adjust to the new reality. The recessionary environment has been enterprise-led so far, with consumer demand holding surprisingly strong. This has not helped MAD companies much, as the overwhelming majority of companies on the landscape are B2B vendors. First to cut spending were scale-ups and other tech companies, which resulted in many Q3 and Q4 sales misses at the MAD startups that target those customers. Now, Global 2000 customers have adjusted their 2023 budgets as well.
We are now in a new normal, with a vocabulary that will echo recessions past for some and will be a whole new muscle to build for younger folks: responsible growth, cost control, CFO oversight, long sales cycles, pilots, ROI.
This is also the big return of corporate governance:

As the tide recedes, many issues that were hidden or deprioritized suddenly emerge in full force. Everyone is forced to pay a lot more attention. VCs on boards are less busy chasing the next shiny object and more focused on protecting their existing portfolio. CEOs are less constantly courted by obsequious potential next-round investors and discover the sheer difficulty of running a startup when the next round of capital at a much higher valuation does not magically materialize every 6 to 12 months.
The MAD world certainly has not been immune to the excesses of the bull market. As an example, scandal emerged at DataRobot after it was revealed that five executives were allowed to sell $32M in stock as secondaries, forcing the CEO to resign (the company was also sued for discrimination).
The silver lining for MAD startups is that spending on data, ML and AI still remains high on the CIO’s priority list. This McKinsey study from December 2022 indicates that 63% percent of respondents say they expect their organizations’ investment in AI to increase over the next three years.
Frozen financing markets
In 2022, both public and private markets effectively shut down and 2023 is looking to be a tough year. The market will separate strong, durable data/AI companies with sustained growth and favorable cash flow dynamics from companies that have mostly been buoyed by capital, hungry for returns in a more speculative environment.
Public markets
As a “hot” category of software, public MAD companies were particularly impacted.
We are overdue for an update to our MAD Public Company Index, but overall, public data & infrastructure companies (the closest proxy to our MAD companies) saw a 51% drawdown compared to the 19% decline for S&P 500 in 2022. Many of these companies traded at significant premiums in 2021 in a low-interest environment. They could very well be oversold at current prices.
- Snowflake was an $89.67B market cap company at the time of our last MAD and went on to reach a high of $122.94B in November 2021. It is currently trading at a $49.55B market cap at the time of writing.
- Palantir was a $49.49B market cap company at the time of our last MAD but traded at $69.89 at its peak in January 2021. It is currently trading at a $19.14B market cap at the time of writing.
- Datadog was a $42.60B market cap company at the time of our last MAD and went on to reach a high of $61.33B in November 2021. It is currently trading at a $25.40B market cap at the time of writing.
- MongoDB was a $30.68B market company at the time of our last MAD and went on to reach a high of $39.03B in November 2021. It is currently trading at a $14.77B market cap at the time of writing.
The late 2020 and 2021 IPO cohorts fared even worse:
- UiPath (2021 IPO) reached a peak of $40.53B in May 2021 and currently trades at $9.04B at the time of writing.
- Confluent (2021 IPO) reached a peak of $24.37B in November 2021 and currently trades at $7.94B at the time of writing.
- C3 AI (2021 IPO) reached a peak of $14.05B in February 2021 and currently trades at $2.76B at the time of writing.
- Couchbase (2021 IPO) reached a peak of $2.18B in May 2021 and currently trades at $0.74B at the time of writing.
As to the small group of “deep tech” companies from our 2021 MAD landscape that went public, it was simply decimated. As an example, within autonomous trucking, companies like TuSimple (which did a traditional IPO), Embark Technologies (SPAC), and Aurora Innovation (SPAC) are all trading near (or even below!) equity raised in the private markets.
Given market conditions, the IPO window has been shut, with little visibility on when it might re-open. Overall IPO proceeds have fallen 94% from 2021, while IPO volume sank 78% in 2022.
Interestingly, two of the very rare 2022 IPOs were MAD companies:
- Mobileye, a world leader in self-driving technologies, went public in October 2022 at a $16.7B valuation. It has more than doubled its valuation since and currently trades at market cap of $36.17B. Intel had acquired the Israeli company for over $15B in 2018 and had originally hoped for a $50B valuation so that IPO was considered disappointing at the time. However, because it went out at the right price, Mobileye is turning out to be a rare bright spot in an otherwise very bleak IPO landscape.
- MariaDB, an open source relational database, went public in December 2022 via SPAC. It saw its stock drop 40% on its first day of trading and now trades at a market cap of $194M (less than the total of what it had raised in private markets before going public).
It’s unclear when the IPO window may open again. There is certainly tremendous pent-up demand from a number of unicorn-type private companies and their investors, but the broader financial markets will need to gain clarity around macro conditions (interest rates, inflation, geopolitical considerations) first.
Conventional wisdom is that when IPOs become a possibility again, the biggest private companies will need to go out first to open the market.
Databricks is certainly one such candidate for the broad tech market and will be even more impactful for the MAD category. Like many private companies, Databricks raised at high valuations, most recently at $38B in its Series H in August 2021 – a high bar given current multiples, even though its ARR is now well over $1B. While the company is reportedly beefing up its systems and processes ahead of a potential listing, CEO Ali Ghodsi expressed in numerous occasions feeling no particular urgency in going public.
Other aspiring IPO candidates on our Emerging MAD Index (also due for an update but still directionally correct) will probably have to wait for their turn.
Private markets
In private markets, this was the year of the Great VC Pullback.
Funding dramatically slowed down. In 2022, startups raised an aggregate of ~$238B, a drop of 31% compared to 2021. The growth market, in particular, effectively died.
Private secondary brokers experienced a burst of activity as many shareholders tried to exit their position in startups perceived as overvalued, including many companies from the MAD landscape (ThoughtSpot, Databricks, Sourcegraph, Airtable, D2iQ, Chainalysis, H20.AI, Scale AI, Dataminr, etc.).

The VC pullback came with a series of market changes that may leave companies orphaned at the time they need the most support. Crossover funds, which had a particularly strong appetite for data/AI startups, have largely exited private markets, focusing on cheaper buying opportunities in public markets. Within VC firms, lots of GPs have or will be moving on, and some solo GPs may not be able (or willing) to raise another fund.
At the time of writing, the venture market is still at a state of standstill.
Many data/AI startups, perhaps even more so than their peers, raised at aggressive valuations in the hot market of the last couple of years. For data infrastructure startups with strong founders, it was pretty common to raise a $20M Series A on $80M-$100M pre-money valuation, which often meant a multiple on next year ARR of 100x or more.
The problem, of course, is that the very best public companies, such as Snowflake, Cloudflare or Datadog, trade at 12x to 18x of next year’s revenues (those numbers are up, reflecting a recent rally at the time of writing).
Startups, therefore, have a tremendous amount of growing to do to get anywhere near their most recent valuations or face significant down rounds (or worse, no round at all). Unfortunately, this growth needs to happen in the context of slower customer demand.
Many startups right now are sitting on solid amounts of cash and don’t have to face their moment of reckoning by going back to the financing market just yet, but that time will inevitably happen unless they become cash-flow positive.
Generative AI: A new financing bubble?
Generative AI (see Part IV) has been the one very obvious exception to the general market doom-and-gloom, a bright light not just in the data/AI world, but in the entire tech landscape.
Particularly as the fortunes of web3/crypto started to turn, AI became the hot new thing once again – not the first time those two areas have traded places in the hype cycle:
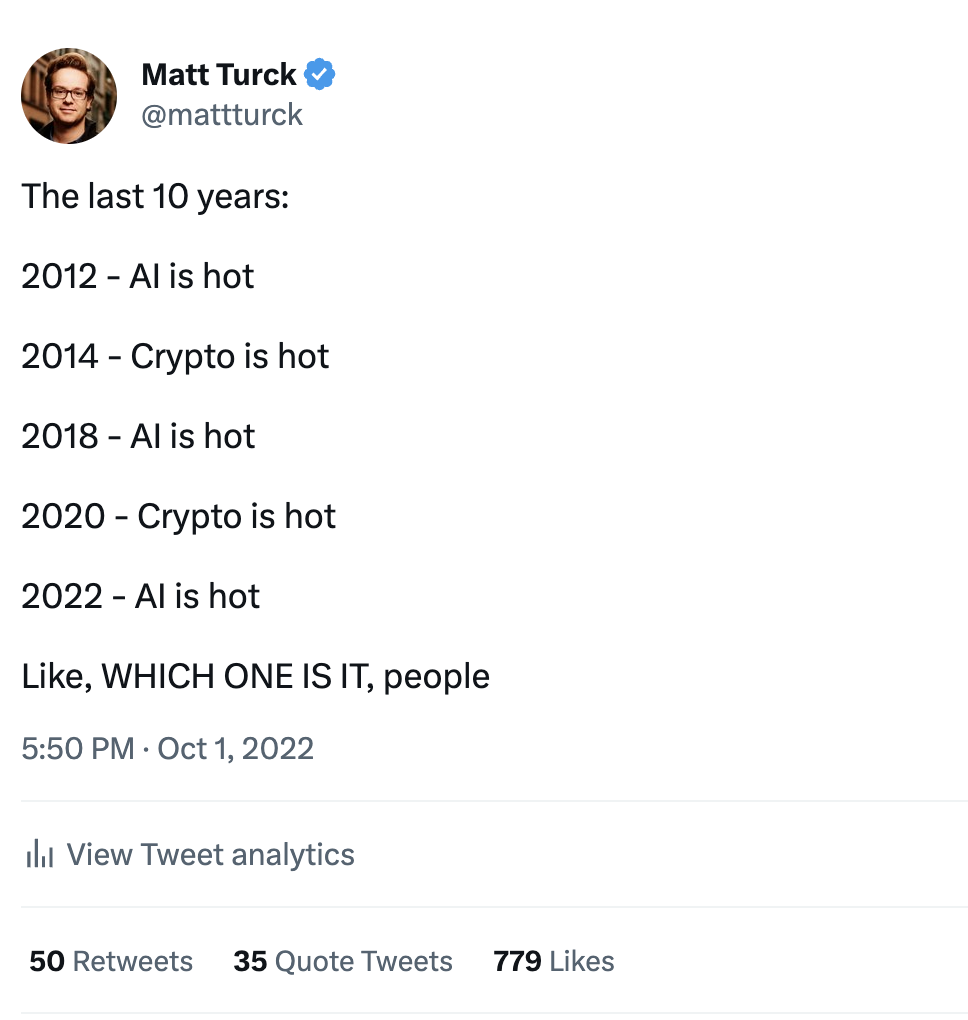
Because generative AI is perceived as a potential “once-every-15-years” type of platform shift in the technology industry, VCs aggressively started pouring money into the space, particularly into founders that came out of research labs like OpenAI, Deepmind, Google Brain, and Facebook AI Research, with several AGI-type companies raising $100M+ in their first rounds of financing.
Generative AI is showing some signs of being a mini-bubble already. As there are comparatively few “assets” available on the market relative to investor interest, valuation is often no object when it comes to winning the deal. The market is showing signs of rapidly adjusting supply to demand, however, as countless generative AI startups are created all of a sudden.
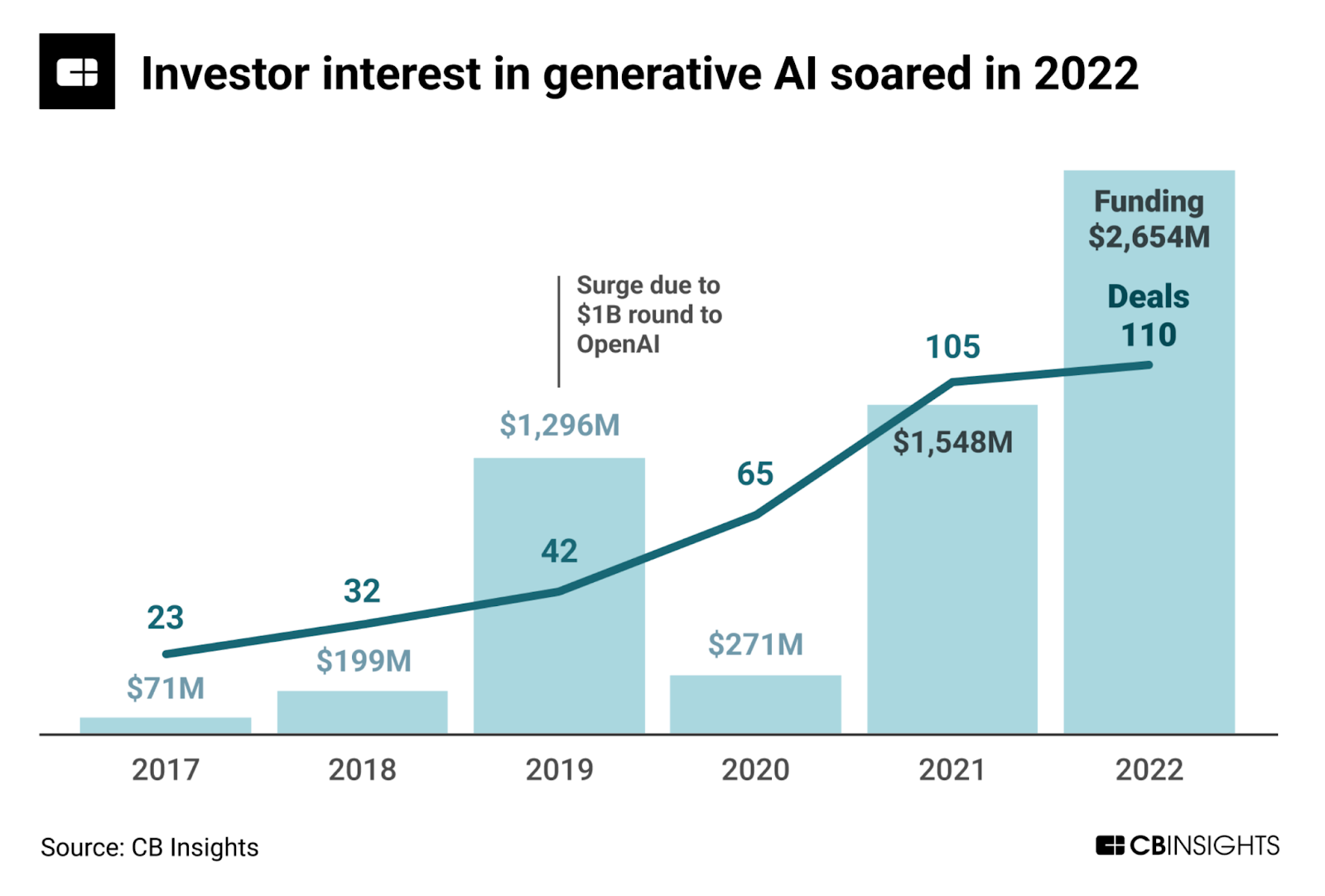
Noteworthy financings in generative AI
OpenAI received a $10B investment from Microsoft in January 2023; Runway ML, an AI-powered video editing platform, raised a $50M Series C at a $500M valuation in December 2022; ImagenAI, an AI-powered photo editing and post-production automation startup, raised $30 million in December 2022; Descript, and AI-powered media editing app, raised $50M in its Series C in November 2022; Mem, an AI-powered note-taking app, raised $23.5M in its Series A in November 2022; Jasper AI, an AI-powered copywriter, raised $125M at a $1.5B valuation in October 2022; Stability AI, the generative AI company behind Stable Diffusion, raised $101M at $1B valuation in October 2022; You, an AI-powered search engine, raised $25M in its Series A financings; Hugging Face, a repository of open source machine learning models, raised $100M in its Series C at a $1B valuation in May 2022; Inflection AI, AGI startup, raised $225M in its first round of equity financing in May 2022; Anthropic, an AI research firm, raised $580M in its Series B (investors including from SBF and Caroline Ellison!) in April 2022; Cohere, an NLP platform, raised $125M in its Series B in February 2022.
Expect a lot more of this. Cohere is reportedly in talks to raise hundreds of millions of dollars in a funding round that could value the startup at more than $6 billion
M&A
2022 was a difficult year for acquisitions, punctuated by the failed $40B acquisition of ARM by Nvidia (which would have affected the competitive landscape of everything from mobile to AI in data centers). The drawdown in the public markets, especially tech stocks, made acquisitions with any stock component more expensive compared to 2021. Late-stage startups with strong balance sheets, on the other hand, generally favored reducing burn instead of making splashy acquisitions. Overall, startup exit values fell by over 90% year over year to $71.4B from $753.2B in 2021.
That said, there were several large acquisitions and a number of (presumably) small tuck-in acquisitions, a harbinger of things to come in 2023, as we expect many more of those in the year ahead (we discuss consolidation in Part III on Data Infrastructure).
Private equity firms may play an outsized role in this new environment, whether on the buy or sell side. Qlik just announced its intent to acquire Talend. This is notable because both companies are owned by Thoma Bravo, who presumably played marriage broker. Progress also just completed its acquisition of MarkLogic, a NoSQL database provider MarkLogic for $355M. MarkLogic, rumored to have revenues “around $100M”, was owned by private equity firm Vector Capital Management.
MAD 2023, Part III: Data infrastructure back to reality

In the hyper-frothy environment of 2019-2021, the world of data infrastructure (nee Big Data) was one of the hottest areas for both founders and VCs.
It was dizzying and fun at the same time, and perhaps a little weird to see so much market enthusiasm for products and companies that are ultimately very technical in nature.
Regardless, as the market has cooled down, that moment is over. While good companies will continue to be created in any market cycle, and “hot” market segments will continue to pop up, the bar has certainly escalated dramatically in terms of differentiation and quality for any new data infrastructure startup to get real interest from potential customers and investors.
Here is our take on some of the key trends in the data infra market in 2023. The first couple trends are higher level and should be interesting to everyone, the others are more in the weeds:
- Brace for impact: bundling and consolidation
- The Modern Data Stack under pressure
- The end of ETL?
- Reverse ETL vs CDP
- Data mesh, products, contracts: dealing with organizational complexity
- [Convergence]
- Bonus: What impact will AI have on data and analytics?
Brace for impact: Bundling and consolidation
If there’s one thing the MAD landscape makes obvious year after year, it’s that the data/AI market is incredibly crowded. In recent years, the data infrastructure market was very much in “let a thousand flowers bloom” mode.
The Snowflake IPO (the biggest software IPO ever) acted as a catalyst for this entire ecosystem. Founders started literally hundreds of companies, and VCs happily funded them (again, and again, and again) within a few months. New categories (e.g., reverse ETL, metrics stores, data observability) appeared and became immediately crowded with a number of hopefuls.
On the customer side, discerning buyers of technology, often found in scale-ups or public tech companies, were willing to experiment and try the new thing with little oversight from the CFO office. This resulted in many tools being tried and purchased in parallel.
Now, the music has stopped.
On the customer side, buyers of technology are under increasing budget pressure and CFO control. While data/AI will remain a priority for many, even during a recessionary period, they have too many tools as it is, and they’re being asked to do more with less. They also have fewer resources to engineer anything. They’re less likely to be experimental or work with immature tools and unproven startups. They’re more likely to pick established vendors that offer tightly integrated suites of products, stuff that “just works.”
This leaves the market with too many data infrastructure companies doing too many overlapping things.
In particular, there’s an ocean of “single-feature” data infrastructure (or MLOps) startups (perhaps too harsh a term, as they’re just at an early stage) that are going to struggle to meet this new bar. Those companies are typically young (1-4 years in existence), and due to limited time on earth, their product is still largely a single feature, although every company hopes to grow into a platform; they have some good customers but not a resounding product-market-fit just yet.
This class of companies has an uphill battle in front of them and a tremendous amount of growing to do in a context where buyers are going to be weary and VC cash is scarce.
Expect the beginning of a Darwinian period ahead. The best (or luckiest, or best funded) of those companies will find a way to grow, expand from a single feature to a platform (say, from data quality to a full data observability platform), and deepen their customer relationships.
Others will be part of an inevitable wave of consolidation, either as a tuck-in acquisition for a bigger platform or as a startup-on-startup private combination. Those transactions will be small, and none of them will produce the kind of returns founders and investors were hoping for. (we are not ruling out the possibility of multi-billion dollar mega deals in the next 12-18 months, but those will most likely require the acquirers to see the light at the end of the tunnel in terms of the recessionary market).
Still, consolidation will be better than simply going out of business. Bankruptcy, an inevitable part of the startup world, will be much more common than in the last few years, as companies cannot raise their next round or find a home.
At the top of the market, the larger players have already been in full product expansion mode. It’s been the cloud hyperscaler’s strategy all along to keep adding products to their platform. Now Snowflake and Databricks, the rivals in a titanic shock to become the default platform for all things data and AI (see the 2021 MAD landscape), are doing the same.
Databricks seems to be on a mission to release a product in just about every box of the MAD landscape. This product expansion has been done almost entirely organically, with a very small number of tuck-in acquisitions along the way – Datajoy and Cortex Labs in 2022. Snowflake has also been releasing features at a rapid pace. It has become more acquisitive as well. It announced three acquisitions in the first couple of months of 2023 already.
Confluent, the public company built on top of the open-source streaming project Kafka, is also making interesting moves by expanding to Flink, a very popular streaming processing engine. It just acquired Immerok. This was a quick acquisition, as Immerok was founded in May 2022 by a team of Flink committees and PMC members, funded with $17M in October and acquired in January 2023.
Some slightly smaller but still unicorn-type startups are also starting to expand aggressively, starting to encroach on other’s territories in an attempt to grow into a broader platform.
As an example, transformation leader dbt Labs first announced a product expansion into the adjacent semantic layer area in October 2022. Then, it acquired an emerging player in the space, Transform (dbt’s blog post provides a nice overview of the semantic layer and metrics store concept) in February 2023.
Some categories in data infrastructure feel particularly ripe for consolidation of some sort – the MAD landscape provides a good visual aid for this, as the potential for consolidation maps pretty closely with the fullest boxes:
ETL and reverse ETL: Over the last three or four years, the market has funded a good number of ETL startups (to move data into the warehouse), as well as a separate group of reverse ETL startups (to move data out of the warehouse). It is unclear how many startups the market can sustain in either category. Reverse ETL companies are under pressure from different angles (see below), and it is possible that both categories may end up merging. ETL company Airbyte acquired Reverse ETL startup Grouparoo. Several companies like Hevo Data position as end-to-end pipelines, delivering both ETL and reverse ETL (with some transformation too), as does data syncing specialist Segment. Could ETL market leader FIvetran acquire or (less likely) merge with one of its Reverse ETL partners like Census or Hightouch?
Data quality and observability: The market has seen a glut of companies that all want to be the “Datadog of data.” What Datadog does for software (ensure reliability and minimize application downtime), those companies want to do for data – detect, analyze and fix all issues with respect to data pipelines. Those companies come at the problem from different angles: Some do data quality (declaratively or through machine learning), others do data lineage, and others do data reliability. Data orchestration companies also play in the space. Many of those companies have excellent founders, are backed by premier VCs and have built quality products. However, they are all converging in the same direction in a context where demand for data observability is still comparatively nascent.
Data catalogs: As data becomes more complex and widespread within the enterprise, there is a need for an organized inventory of all data assets. Enter data catalogs, which ideally also provide search, discovery and data management capabilities. While there is a clear need for the functionality, there are also many players in the category, with smart founders and strong VC backing, and here as well, it is unclear how many the market can sustain. It is also unclear whether data catalogs can be separate entities outside of broader data governance platforms long term.
MLOps: While MLOps sits in the ML/AI section of the MAD landscape, it is also infrastructure and it is likely to experience some of the same circumstances as the above. Like the other categories, MLOps plays an essential role in the overall stack, and it is propelled by the rising importance of ML/AI in the enterprise. However, there is a large number of companies in the category, most of which are well-funded but early on the revenue front. They started from different places (model building, feature stores, deployment, transparency, etc.), but as they try to go from single feature to a broader platform, they are on a collision course with each other. Also, many of the current MLOps companies have primarily focused on selling to scale-ups and tech companies. As they go upmarket, they may start bumping into the enterprise AI platforms that have been selling to Global 2000 companies for a while, like Dataiku, Datarobot, H2O, as well as the cloud hyperscalers.
The modern data stack under pressure
A hallmark of the last few years has been the rise of the “Modern Data Stack” (MDS). Part architecture, part de facto marketing alliance amongst vendors, the MDS is a series of modern, cloud-based tools to collect, store, transform and analyze data. At the center of it, there’s the cloud data warehouse (Snowflake, etc.). Before the data warehouse, there are various tools (Fivetran, Matillion, Airbyte, Meltano, etc.) to extract data from their original sources and dump it into the data warehouse. At the warehouse level, there are other tools to transform data, the “T” in what used to be known as ETL (extract transform load) and has been reversed to ELT (here, dbt Labs reigns largely supreme). After the data warehouse, there are other tools to analyze the data (that’s the world of BI, for business intelligence) or extract the transformed data and plug it back into SaaS applications (a process known as “reverse ETL”).
Up until recently, the MDS was a fun but little world. As Snowflake’s fortunes kept rising, so did the entire ecosystem around it. Now, the world has changed. As cost control becomes paramount, some may question the approach that is at the heart of the modern data stack: Dump all your data somewhere (a data lake, lakehouse or warehouse) and figure out what to do with it later, which turns out to be expensive and not always that useful.
Now the MDS is under pressure. In a world of cost control and rationalization, it’s almost too obvious a target. It’s complex (as customers need to stitch everything together and deal with multiple vendors). It’s expensive (as every vendor wants their margin and also because you need an in-house team of data engineers to make it all work). And it’s arguably elitist (as those are the most bleeding-edge, best-in-breed tools, requiring customers to be sophisticated both technically and in terms of use cases), serving the needs of the few.
What happens when MDS companies stop being friendly and start competing with one another for smaller customer budgets?
As an aside, the complexity of the MDS has given rise to a new category of vendors that “package” various products under one fully managed platform (as mentioned above, a new box in the 2023 MAD featuring companies like Y42 or Mozart Data). The underlying vendors are some of the usual suspects in MDS, but most of those platforms abstract away both the business complexity of managing several vendors and the technical complexity of stitching together the various solutions.
The end of ETL?
As a twist on the above, there’s a parallel discussion in data circles as to whether ETL should even be part of data infrastructure going forward. ETL, even with modern tools, is a painful, expensive and time-consuming part of data engineering.
At its Re:Invent conference last November, Amazon asked, “What if we could eliminate ETL entirely? That would be a world we would all love. This is our vision, what we’re calling a zero ETL future. And in this future, data integration is no longer a manual effort”, announcing support for a “zero-ETL” solution that tightly integrates Amazon Aurora with Amazon Redshift. Under that integration, within seconds of transactional data being written into Aurora, the data is available in Amazon Redshift.
The benefits of an integration like this are obvious: No need to build and maintain complex data pipelines, no duplicate data storage (which can be expensive), and always up-to-date.
Now, an integration between two Amazon databases in itself is not enough to lead to the end of ETL alone, and there are reasons to be skeptical that a Zero ETL future would happen soon.
But then again, Salesforce and Snowflake also announced a partnership to share customer data in real-time across systems without moving or copying data, which falls under the same general logic. Before that, Stripe had launched a data pipeline to help users sync payment data with Redshift and Snowflake.
The concept of change data capture is not new, but it’s gaining steam. Google already supports change data capture in BigQuery. Azure Synapse does the same by pre-integrating Azure Data Factory. There is a rising generation of startups in the space like Estuary* and Upsolver. It seems that we’re heading towards a hybrid future where analytic platforms will blend in streaming, integration with data flow pipelines and Kafka PubSub feeds.
Reverse ETL vs. CDP
Another somewhat-in-the-weeds but fun-to-watch part of the landscape has been the tension between Reverse ETL (again, the process of taking data out of the warehouse and putting it back into SaaS and other applications) and Customer Data Platforms (products that aggregate customer data from multiple sources, run analytics on them like segmentation, and enable actions like marketing campaigns).
Over the last year or so, the two categories started converging into one another.
Reverse ETL companies presumably learned that just being a pipeline on top of a data warehouse wasn’t commanding enough wallet share from customers and that they needed to go further in providing value around customer data. Many Reverse ETL vendors now position themselves as CDP from a marketing standpoint.
Meanwhile, CDP vendors learned that being another repository where customers needed to copy massive amounts of data was at odds with the general trend of centralization of data around the data warehouse (or lake or lakehouse). Therefore, CDP vendors started offering integration with the main data warehouse and lakehouse providers. See, for example, ActionIQ* launching HybridCompute, mParticle launching Warehouse Sync, or Segment introducing Reverse ETL capabilities. As they beef up their own reverse ETL capabilities, CDP companies are now starting to sell to a more technical audience of CIO and analytics teams, in addition to their historical buyers (CMOs).
Where does this leave Reverse ETL companies? One way they could evolve is to become more deeply integrated with the ETL providers, which we discussed above. Another way would be to further evolve towards becoming a CDP by adding analytics and orchestration modules.
Data mesh, products, contracts: Dealing with organizational complexity
As just about any data practitioner knows firsthand: success with data is certainly a technical and product effort, but it also very much revolves around process and organizational issues.
In many organizations, the data stack looks like a mini-version of the MAD landscape. You end up with a variety of teams working on a variety of products. So how does it all work together? Who’s in charge of what?
A debate has been raging in data circles about how to best go about it. There are a lot of nuances and a lot of discussions with smart people disagree on, well, just about any part of it, but here’s a quick overview.
We highlighted the data mesh as an emerging trend in the 2021 MAD landscape and it’s only been gaining traction since. The data mesh is a distributed, decentralized (not in the crypto sense) approach to managing data tools and teams. Note how it’s different from a data fabric – a more technical concept, basically a single framework to connect all data sources within the enterprise, regardless of where they’re physically located.
The data mesh leads to a concept of data products – which could be anything from a curated data set to an application or an API. The basic idea is that each team that creates the data product is fully responsible for it (including quality, uptime, etc.). Business units within the enterprise then consume the data product on a self-service basis.
A related idea is data contracts: “API-like agreements between software engineers who own services and data consumers that understand how the business works in order to generate well-modeled, high-quality, trusted, real-time data.” There have been all sorts of fun debates about the concept. The essence of the discussion is whether data contracts only make sense in very large, very decentralized organizations, as opposed to 90% of smaller companies.
Bonus: How will AI impact data infrastructure?
With the current explosive progress in AI, here’s a fun question: Data infrastructure has certainly been powering AI, but will AI now impact data infrastructure?
Some data infrastructure providers have already been using AI for a while – see, for example, Anomalo leveraging ML to identify data quality issues in the data warehouse. But with the rise of Large Language Models, there’s a new interesting angle. In the same way LLMs can create conventional programming code, they can also generate SQL, the language of data analysts. The idea of enabling non-technical users to search analytical systems is not new, and various providers already support variations of it, see ThoughtSpot, Power BI or Tableau. Here are some good pieces on the topic: LLM Implications on Analytics (and Analysts!) by Tristan Handy of dbt Labs and The Rapture and the Reckoning by Benn Stancil of Mode.
MAD 2023, part IV: Trends in ML/AI

The excitement! The drama! The action!
Everybody is talking breathlessly about AI all of a sudden. OpenAI gets a $10B investment. Google is in Code Red. Sergey is coding again. Bill Gates says what’s been happening in AI in the last 12 months is “every bit as important as the PC or the internet.” Brand new startups are popping up (20 generative AI companies just in the winter ’23 YC batch). VCs are back to chasing pre-revenue startups at billions of valuation.
So what does it all mean? Is this one of those breakthrough moments that only happen every few decades? Or just the logical continuation of work that has been happening for many years? Are we in the early days of a true exponential acceleration? Or at the top of one of those hype cycles, as many in tech are desperate for the next big platform shift after social and mobile and the crypto headfake?
The answer to all those questions is… yes.
Let’s dig in:
- AI goes mainstream
- Generative AI becomes a household name
- The inevitable backlash
- [Big progress in reinforcement learning]
- [The emergence of a new AI political economy]
- [Big Tech has a head start over startups]
- [Are we getting closer to AGI?]
AI goes mainstream
It had been a wild ride in the world of AI throughout 2022, but what truly took things to a fever pitch was, of course, the public release of Open’s AI conversational bot, ChatGPT, on November 30, 2022. ChatGPT, a chatbot with an uncanny ability to mimic a human conversationalist, quickly became the fastest-growing product, well, ever.

For whoever was around then, the experience of first interacting with ChatGPT was reminiscent of the first time they interacted with Google in the late nineties. Wait, is it really that good? And that fast? How is this even possible? Or the iPhone when it first came out. Basically, a first glimpse into what feels like an exponential future.
ChatGPT immediately took over every business meeting, conversation, dinner, and, most of all, every bit of social media. Screenshots of smart, amusing and occasionally wrong replies by ChatGPT became ubiquitous on Twitter. We all just had to chat about ChatGPT.
By January, ChatGPT had reached 100M users. A whole industry of overnight experts emerged on social media, with a never-ending bombardment of explainer threads coming to the rescue of anyone who had been struggling with ChatGPT (literally, no one asked) and ambitious TikTokers teaching us the ways of prompt engineering, meaning providing the kind of input that would elicit the best response from ChatGPT.
After being exposed to a non-stop barrage of tweets on the topic, this was the sentiment:
ChatGPT continued to accumulate feats. It passed the Bar. It passed the US medical licensing exam.
ChatGPT didn’t come out of nowhere. AI circles had been buzzing about GPT-3 since its release in June 2020, raving about a quality of text output that was so high that it was difficult to determine whether or not it was written by a human. But GPT-3 was provided as an API targeting developers, not the broad public.
The release of ChatGPT (based on GPT 3.5) feels like the moment AI truly went mainstream in the collective consciousness.
We are all routinely exposed to AI prowess in our everyday lives through voice assistants, auto-categorization of photos, using our faces to unlock our cell phones, or receiving calls from our banks after an AI system detected possible financial fraud. But, beyond the fact that most people don’t realize that AI powers all of those capabilities and more, arguably, those feel like one-trick ponies.
With ChatGPT, suddenly, you had the experience of interacting with something that felt like an all-encompassing intelligence.
The hype around ChatGPT is not just fun to talk about. It’s very consequential because it has forced the industry to react aggressively to it, unleashing, among other things, an epic battle for internet search.
The exponential acceleration of generative AI
But, of course, it’s not just ChatGPT. For anyone who was paying attention, the last few months saw a dizzying succession of groundbreaking announcements seemingly every day. With AI, you could now create audio, code, images, text and videos.
What was at some point called synthetic media (a category in the 2021 MAD landscape) became widely known as generative AI: A term still so new that it does not have an entry in Wikipedia at the time of writing.
The rise of generative AI has been several years in the making. Depending on how you look at it, it traces it roots back to deep learning (which is several decades old but dramatically accelerated after 2012) and the advent of generative Adversarial Networks (GAN) in 2014, led by Ian Goodfellow, under the supervision of his professor and Turing Award recipient, Yoshua Bengio. Its seminal moment, however, came barely five years ago, with the publication of the transformer (the “T” in GPT) architecture in 2017, by Google.
Coupled with rapid progress in data infrastructure, powerful hardware and a fundamentally collaborative, open source approach to research, the transformer architecture gave rise to the Large Language Model (LLM) phenomenon.
The concept of a language model itself is not particularly new. A language model’s core function is to predict the next word in a sentence.
However, transformers brought a multimodal dimension to language models. There used to be separate architectures for computer vision, text and audio. With transformers, one general architecture can now gobble up all sorts of data, leading to an overall convergence in AI.
In addition, the big change has been the ability to massively scale those models.
OpenAI’s GPT models are a flavor of transformers that it trained on the Internet, starting in 2018. GPT-3, their third-generation LLM, is one of the most powerful models currently available. It can be fine-tuned for a wide range of tasks – language translation, text summarization, and more. GPT-4 is expected to be released sometime in 2024 and is rumored to be even more mind-blowing. (ChatGPT is based on GPT 3.5, a variant of GPT-3).
OpenAI also played a driving role in AI image generation. In early 2021, it released CLIP, an open source, multimodal, zero-shot model. Given an image and text descriptions, the model can predict the most relevant text description for that image without optimizing for a particular task.
OpenAI doubled down with DALL-E, an AI system that can create realistic images and art from a description in natural language. The particularly impressive second version, DALL-E 2, was broadly released to the public at the end of September 2022.
There are already multiple contenders vying to be the best text-to-image model. Midjourney, entered open beta in July 2022 (it’s currently only accessible through their Discord*). Stable Diffusion, another impressive model, was released in August 2022. It originated through the collaboration of several entities, in particular Stability AI, CompVis LMU, and Runway ML. It offers the distinction of being open source, which DALL-E 2 and Midjourney are not.
Those developments are not even close to the exponential acceleration of AI releases that occurred since the middle of 2022.
In September 2022, OpenAI released Whisper, an automatic speech recognition (ASR) system that enables transcription in multiple languages as well as translation from those languages into English. Also in September 2022, MetaAI released Make-A-Video, an AI system that generates videos from text.
In October 2022, CSM (Common Sense Machines) released CommonSim-1, a model to create 3D worlds.
In November 2022, MetaAI released CICERO, the first AI to play the strategy game Diplomacy at a human level, described as “a step forward in human-AI interactions with AI that can engage and compete with people in gameplay using strategic reasoning and natural language.”
In January 2023, Google Research announced MusicLM, “a model generating high-fidelity music from text descriptions such as “a calming violin melody backed by a distorted guitar riff.”
Another particularly fertile area for generative AI has been the creation of code.
In 2021, OpenAI released Codex, a model that translates natural language into code. You can use codex for tasks like “turning comments into code, rewriting code for efficiency, or completing your next line in context.” Codex is based on GPT-3 and was also trained on 54 million GitHub repositories. In turn, GitHub Copilot uses Codex to suggest code right from the editor.
In turn, Google’s DeepMind released Alphacode in February 2022 and Salesforce released CodeGen in March 2022. Huawei introduced PanGu-Coder in July 2022.
The inevitable backlash
The exponential acceleration in AI progress over the last few months has taken most people by surprise. It is a clear case where technology is way ahead of where we are as humans in terms of society, politics, legal framework and ethics. For all the excitement, it was received with horror by some and we are just in the early days of figuring out how to handle this massive burst of innovation and its consequences.
ChatGPT was pretty much immediately banned by some schools, AI conferences (the irony!) and programmer websites. Stable Diffusion was misused to create an NSFW porn generator, Unstable Diffusion, later shut down on Kickstarter. There are allegations of exploitation of Kenyan workers involved in the data labeling process. Microsoft/GitHub is getting sued for IP violation when training Copilot, accused of killing open source communities. Stability AI is getting sued by Getty for copyright infringement. Midjourney might be next (Meta is partnering with Shutterstock to avoid this issue). When an A.I.-generated work, “Théâtre d’Opéra Spatial,” took first place in the digital category at the Colorado State Fair, artists around the world were up in arms.
AI and jobs
A lot of people’s reaction when confronted with the power of generative AI is that it will kill jobs. The common wisdom in years past was that AI would gradually automate the most boring and repetitive jobs. AI would kill creative jobs last because creativity is the most quintessentially human trait. But here we are, with generative AI going straight after creative pursuits.
Artists are learning to co-create with AI. Many are realizing that there’s a different kind of skill involved. Jason Allen, the creator of Théâtre d’Opéra Spatial, explains that he spent 80 hours and created 900 images before getting to the perfect combination.
Similarly, coders are figuring out how to work alongside Copilot. AI leader, Andrej Karpathy, says Copilot already writes 80% of his code. Early research seems to indicate significant improvements in developer productivity and happiness. It seems that we’re evolving towards a co-working model where AI models work alongside humans as “pair programmers” or “pair artists.”
Perhaps AI will lead to the creation of new jobs. There’s already a marketplace for selling high-quality text prompts.
AI bias
A serious strike against generative AI is that it is biased and possibly toxic. Given that AI reflects its training dataset, and considering GPT and others were trained on the highly biased and toxic Internet, it’s no surprise that this would happen.
Early research has found that image generation models, like Stable Diffusion and DALL-E, not only perpetuate but also amplify demographic stereotypes.
At the time of writing, there is a controversy in conservative circles that ChatGPT is painfully woke.
AI disinformation
Another inevitable question is all the nefarious things that can be done with such a powerful new tool. New research shows AI’s ability to simulate reactions from particular human groups, which could unleash another level in information warfare.
Gary Marcus warns us about AI’s Jurassic Park moment – how disinformation networks would take advantage of ChatGPT, “attacking social media and crafting fake websites at a volume we have never seen before.”
AI platforms are moving promptly to help fight back, in particular by detecting what was written by a human vs. what was written by an AI. OpenAI just launched a new classifier to do that, which is beating the state of the art in detecting AI-generated text.
Is AI content just… boring?
Another strike against generative AI is that it could be mostly underwhelming.
Some commentators worry about an avalanche of uninteresting, formulaic content meant to help with SEO or demonstrate shallow expertise, not dissimilarly from what content farms (a la Demand Media) used to do.
As Jack Clark pouts in his OpenAI newsletter: “Are we building these models to enrich our own experience, or will these models ultimately be used to slice and dice up human creativity and repackage and commoditize it? Will these models ultimately enforce a kind of cultural homogeneity acting as an anchor forever stuck in the past? Or could these models play their own part in a new kind of sampling and remix culture for music?”
AI hallucination
Finally, perhaps the biggest strike against generative AI is that it is often just wrong.
ChatGPT, in particular, is known for “hallucinating,” meaning making up facts while conveying them with utter self-confidence in its answers.
Leaders in AI have been very explicit about it, like OpenAI’s CEO Sam Altman here:

The big companies are well aware of the risk.
MetaAI introduced Galactica, a model designed to assist scientists, in November 2022 but pulled it after three days. The model generated both convincing scientific content and convincing (and occasionally racist) content.
Google kept its LaMBDA model very private, available to only a small group of people through AI Test Kitchen, an experimental app. The genius of Microsoft working with OpenAI as an outsourced research arm was that OpenAI, as a startup, could take risks that Microsoft could not. One can assume that Microsoft was still reeling from the Tay disaster in 2016.
However, Microsoft was forced by competition (or could not resist the temptation) to open Pandora’s box and add GPT to its Bing search engine. That did not go as well as it could have, with Bing threatening users or declaring their love to them.
Subsequently, Google also rushed to market its own ChatGPT competitor, the interestingly named Bard. This did not go well either, and Google lost $100B in market capitalization after Bard made factual errors in its first demo.
The business of AI: Big Tech has a head start over startups
The question on everyone’s minds in venture and startup circles: what is the business opportunity? The recent history of technology has seen a major platform shift every 15 years or so for the last few decades: the mainframe, the PC, the internet and mobile. Many thought crypto and blockchain architecture was the next big shift but, at a minimum, the jury is out on that one for now.
Is generative AI that once-every-15-years kind of generational opportunity that is about to unleash a massive new wave of startups (and funding opportunities for VCs)? Let’s look into some of the key questions.
Will incumbents own the market?
The success story in Silicon Valley lore goes something like this: big incumbent owns a large market but gets entitled and lazy; little startup comes up with a 10x better technology; against the odds and through great execution (and judicious from the VCs on the board, of course), little startup hits hyper-growth, becomes big and overtakes the big incumbent.
The issue in AI is that little startups are facing a very specific type of incumbents – the world’s biggest technology companies, including Alphabet/Google, Microsoft, Meta/Facebook and Amazon/AWS.
Not only are those incumbents not “lazy,” but in many ways, they’ve been leading the charge in innovation in AI. Google thought of itself as an AI company from the very beginning (“Artificial intelligence would be the ultimate version of Google… that is basically what we work on,” said Larry Page in 2000). The company produced many key innovations in AI, including transformers, as mentioned, Tensorflow and the Tensor Processing Units (TPU). Meta/Facebook We talked about how Transformers came from Google, but that’s just one of the many innovations that the company has released over the years. Meta/Facebook created PyTorch, one of the most important and used machine learning frameworks. Amazon, Apple, Microsoft, Netflix have all produced groundbreaking work.
Incumbents also have some of the very best research labs, experienced machine learning engineers, massive amounts of data, tremendous processing power and enormous distribution and branding power.
And finally, AI is likely to become even more of a top priority as it is becoming a major battleground. As mentioned earlier, Google and Microsoft are now engaged in an epic battle in search, with Microsoft viewing GPT as an opportunity to breathe new life into Bing and Google, considering it a potentially life-threatening alert.
Meta/Facebook has made a huge bet in a very different area – the metaverse. That bet continues to prove to be very controversial. Meanwhile, it’s sitting on some of the best AI talent and technology in the world. How long until it reverses course and starts doubling or tripling down on AI?
Is AI just a feature?
Beyond Bing, Microsoft quickly rolled out GPT in Teams. Notion launched NotionAI, a new GPT-3-powered writing assistant. Quora launched Poe, its own AI chatbot. Customer service leaders Intercom and Ada* announced GPT-powered features.
How quickly and seemingly easily companies are rolling out AI-powered features seems to indicate that AI is going to be everywhere soon. In prior platform shifts, a big part of the story was that every company out there adopted the new platform: Businesses became internet-enabled, everyone built a mobile app, etc.
We don’t expect anything different to happen here. We’ve long argued in prior posts that the success of data and AI technologies is that they eventually will become ubiquitous and disappear in the background. It’s the ransom of success for enabling technologies to become invisible.
What are the opportunities for startups?
However, as history has shown time and again, don’t discount startups. Give them a technology breakthrough, and entrepreneurs will find a way to build great companies.
Yes, when mobile appeared, all companies became mobile-enabled. However, founders built great startups that could not have existed without the mobile platform shift – Uber being the most obvious example.
Who will be the Uber of generative AI?
The new generation of AI Labs is perhaps building the AWS, rather than Uber, of generative AI. OpenAI, Anthropic, Stability AI, Adept, Midjourney and others are building broad horizontal platforms upon which many applications are already being created. It is an expensive business, as building large language models is extremely resource intensive, although perhaps costs are going to drop rapidly. The business model of those platforms is still being worked out. OpenAI launched ChatGPT Plus, a paying premium version of ChatGPT. Stability AI plans on monetizing its platform by charging for customer-specific versions.
There’s been an explosion of new startups leveraging GPT, in particular, for all sorts of generative tasks, from creating code to marketing copy to videos. Many are derided as being a “thin layer” on top of GPT. There’s some truth to that, and their defensibility is unclear. But perhaps that’s the wrong question to ask. Perhaps those companies are just the next generation of software rather than AI companies. As they build more functionality around things like workflow and collaboration on top of the core AI engine, they will be no more, but also no less, defensible than your average SaaS company.
We believe that there are many opportunities to build great companies: vertical-specific or task-specific companies that will intelligently leverage generative AI for what it is good at. AI-first companies that will develop their own models for tasks that are not generative in nature. LLM-ops companies that will provide the necessary infrastructure. And so many more.
This next wave is just getting started, and we can’t wait to see what happens.
Matt Turck is a VC at FirstMark, where he focuses on SaaS, cloud, data, ML/AI, and infrastructure investments. Matt also organizes Data Driven NYC, the largest data community in the U.S.
DataDecisionMakers
Welcome to the VentureBeat community!
DataDecisionMakers is where experts, including the technical people doing data work, can share data-related insights and innovation.
If you want to read about cutting-edge ideas and up-to-date information, best practices, and the future of data and data tech, join us at DataDecisionMakers.
You might even consider contributing an article of your own!
Author: Matt Turck
Source: Venturebeat
